

Table of Contents
In the world of vulnerability management, triage is the gatekeeper. It ensures the quality of reports before they enter the remediation pipeline. However, it is also a repetitive and time-consuming task. Verifying scope, identifying duplicates, or validating CVSS severity requires constant attention, even as the volume of reports continues to grow.
Facing this challenge, we asked ourselves a practical question: can Artificial Intelligence absorb the load of low-value tasks to allow analysts to focus on complex technical expertise?
This is the goal of the Proof of Concept (POC) presented here. Far from wanting to replace humans, this project aimed to build a “Triage Assistant” capable of reliably pre-qualifying submissions. But not at any cost: the critical nature of vulnerability data imposed a major constraint—a strict ban on public LLMs in favor of an internal, siloed infrastructure.
In this article, we detail how we built this assisted triage workflow at Yogosha, Offensive Security Platform: from choosing an architecture based on n8n and private AI agents, to the concrete results obtained in detecting duplicates and out-of-scope reports.
Technical solution
Choosing the tools
Before implementing the process, we needed a technical framework consistent with our security constraints. The golden rule was simple: no public LLMs. Reports contain sensitive information, so all analysis had to be strictly hosted within our internal environment.
The solution also needed to:
- easily call our APIs
- integrate seamlessly with our MCP server (if needed)
- manipulate and transform data
- evolve quickly based on our needs
We put several candidates to the test:
- n8n, for its wealth of connectors and workflow-oriented logic
- an in-app workflow via the LLPhant library, integrated directly into the platform
- an external application built with CrewAI or LangChain/LangGraph
After several experiments, n8n came out on top. It offered the best compromise: a very rich ecosystem of components, rapid iteration capabilities, and most importantly, a native evaluation system to measure the quality of results.
Once the stack was chosen, the next step was to lay out a clear architecture and see how all the elements would fit together.
Architecture
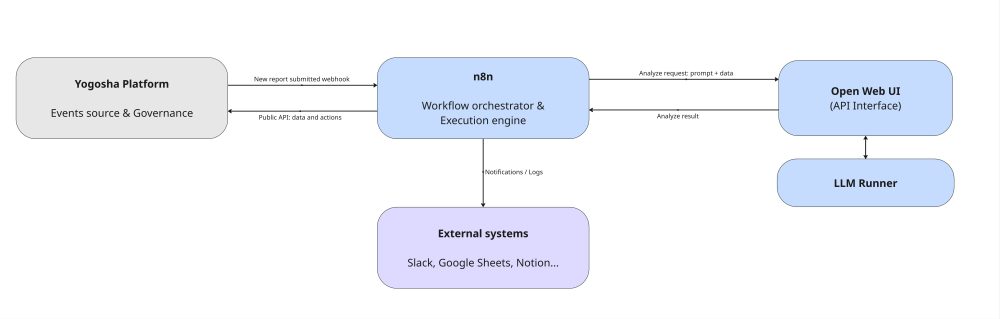
The architecture relies on n8n as the conductor. The Yogosha platform acts as the event source: when a new report is submitted, it triggers a webhook to n8n, which initiates the triage.
n8n then pilots the different processing steps, specifically calling the Yogosha Private AI (exposed via Open WebUI). This is what analyzes the reports, powered by a local LLM engine.
In parallel, n8n interacts with the Yogosha platform via its public API and can send results to other systems (Slack, Google Spreadsheets, Notion, etc.) thanks to its numerous integrations.
The result is a clear, decoupled, and extensible event-driven flow: n8n handles coordination, the platform manages business data, and the AI provides analytical intelligence.
Workflows
Just as a human triager would, our process follows three key successive steps.
The first version was a monolithic workflow—a single “block” chaining all steps together. We quickly saw the limits of this organization: it was impossible to automatically test isolated parts, and every modification required re-checking everything.
We therefore broke it down into sub-workflows, which are easier to maintain and make reliable.
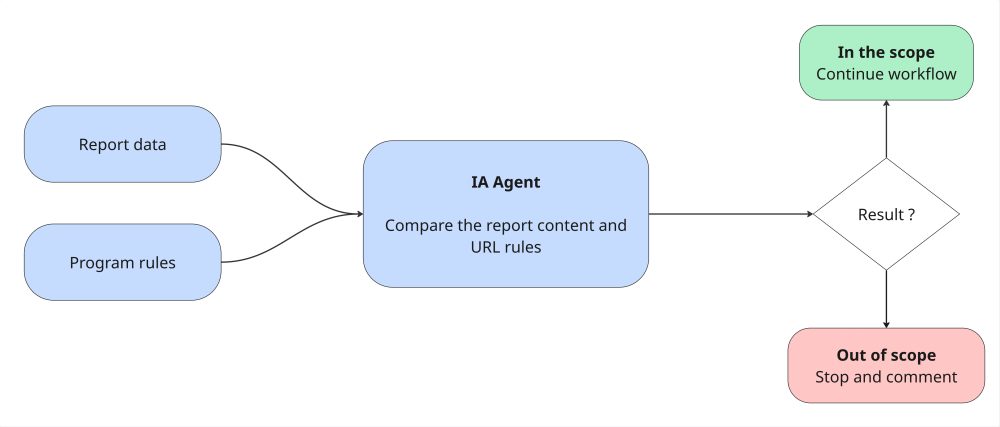
Scope verification
In this first step, we check if the submitted report actually falls within the program’s scope. We implemented a first AI agent that analyzes the report content (title, description, and proof of concept) to compare them with the program’s authorized and out-of-scope targets. This allows us to immediately define if the report is legitimate or if we can warn the user directly.
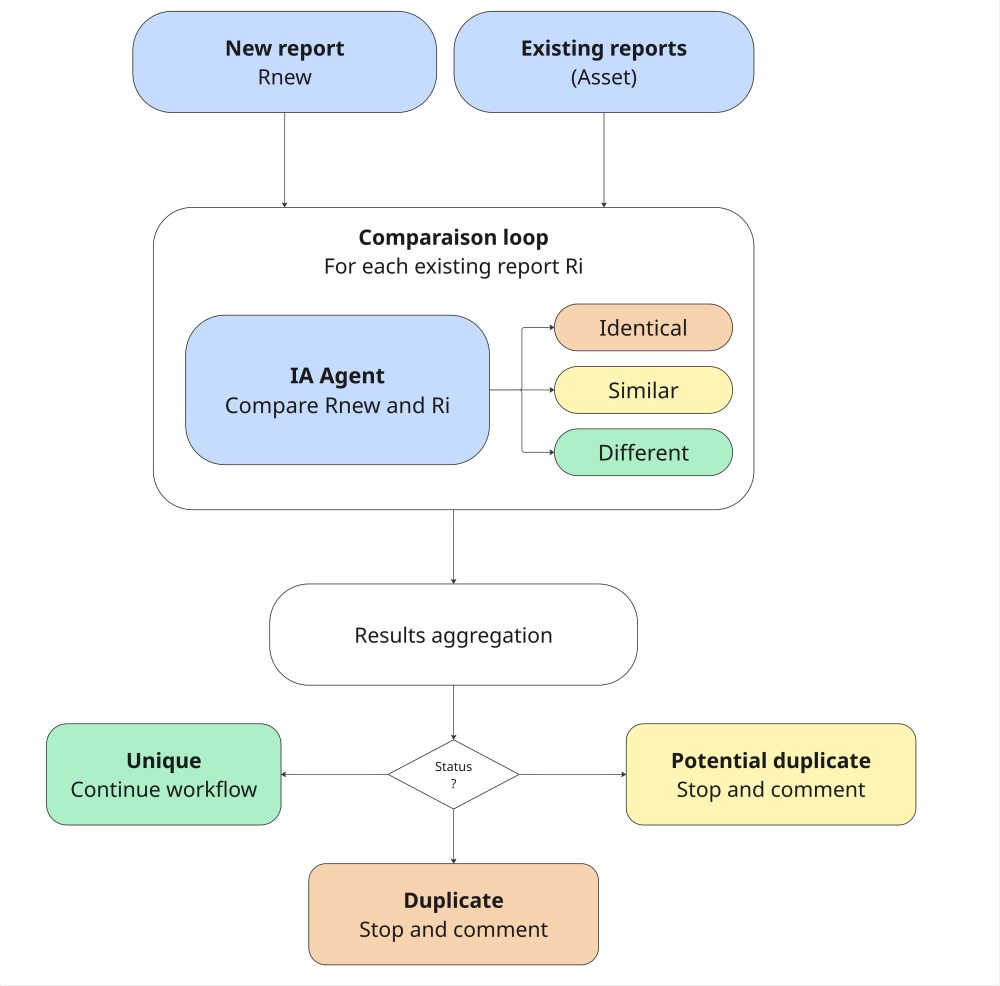
The hunt for duplicates
The next step is determining if a report has already been submitted for the same vulnerability. We defined an AI agent that compares two reports to determine if they are:
- identical
- similar
- different
This nuance is crucial to help the human triager make the final call. Indeed, two reports on the same flaw but on two different resources (e.g., two distinct API endpoints) could be considered a duplicate if the underlying code is common, or as two distinct bugs. This arbitrage often depends on the program context, and our current workflow leaves this final decision to the human.
Concretely, the workflow retrieves existing reports on the concerned asset, and the AI compares them one by one. If a duplicate (or potential duplicate) is detected, the workflow stops and submits a detailed comment.
CVSS validation
The final step aims to verify if the report is a confirmed bug and if the indicated severity score (CVSS) is relevant. Since we couldn’t yet achieve results meeting our quality standards, this part of the triage was put on hold to focus on the other steps that deliver immediate added value.
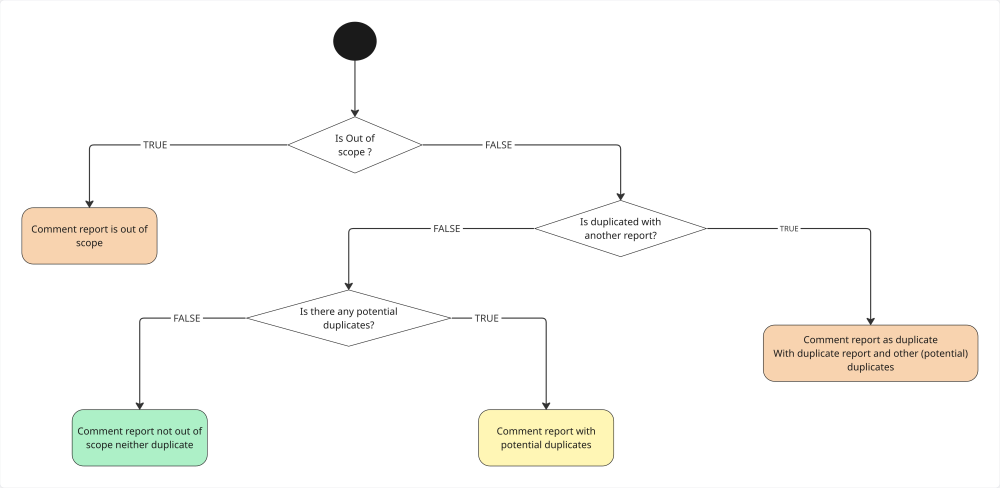
IA recommendation
Throughout the triage process, the workflow looks for a valid reason to refuse a report to alert the triager.
If an anomaly is detected (out-of-scope or duplicate): A private comment is posted via the API with the details of the analysis. It is visible only to the triager.
If everything is correct: The workflow posts a comment to clarify to the client that the automated analysis detected nothing abnormal.
A word from the Cyber Team
Manual verification of scopes and duplicates took up a significant part of our time. This tool allowed us to automate these basic checks. Now, we can immediately dedicate ourselves to technical expertise, with much more fluid decision-making.
Mohamed Foudhaili
Make it reliable
MCP or API?
In the very first version, we tried using the Yogosha MCP server to retrieve data needed for triage. This approach turned out to be too heavy for the AI: tool definitions were very verbose, and responses (like lists of reports) were too voluminous, “drowning” the model. By switching back to classic API calls, we guaranteed deterministic behavior and much better performance.
Splitting into sub-workflows
The modular breakdown was a lifesaver. Like microservices, this approach requires an initial effort to clearly define inputs and outputs for each block. But unlike the monolithic workflow where everything was mixed up, this breakdown clarified responsibilities and limited side effects. Above all, it greatly facilitated the implementation of evaluations.
Validation and LLM reliability
The crucial step when integrating a triage assistant is validating the quality of the analysis. By definition, AI agents generate non-deterministic results; it was therefore imperative to have a mechanism guaranteeing output compliance with our expectations.
To meet this challenge, we used n8n’s “evaluation” feature. This tool allows running a workflow on a specific dataset and comparing the results against a “ground truth”.
We built a dataset of over 300 real reports, taken from our internal Yogosha programs, which had already been manually triaged and closed. The workflow was run on this history, and its recommendations were automatically compared to the original human decisions.
Although time-consuming, this iterative process was indispensable for measuring the workflow’s real performance and visualizing the impact of each modification.
During this first iteration, we achieved these results:
- out-of-scope detection: the workflow identifies 99% of cases, with a false positive rate limited to 10%.
- duplicate management: the AI detects the presence of a duplicate in 100% of cases. However, the precision in identifying the specific original report (the “parent”) sits at 40%, leaving room for improvement.
Monitoring and continuous improvement
Moving to the beta phase doesn’t mark the end of the process, but the start of active surveillance. To ensure the relevance of suggestions over the long term, we implemented a real-time feedback loop.
Concretely, we systematically capture every interaction to compare the AI’s recommendation with the human expert’s final decision. This data feeds a tracking dashboard that allows us to visualize:
- global accuracy: a key indicator to measure the alignment rate between AI and human.
- performance by category: a granular analysis of duplicate detection and out-of-scope reports.
- recent activity: a log of the latest triages to quickly identify divergences.
This tool is indispensable for managing the assistant’s reliability and adjusting our models continuously.
Conclusion and key takeaways
Deploying this first AI workflow offered us much more than simple automation: it helped us understand that the success of such a project relies less on the algorithm itself than on the robustness of the validation frameworks. These are what transform a technical hunch into a reliable, data-driven tool.
Using real data actually revealed an interesting paradox: our “ground truth” (our internal report history) had its own biases. The workflow inadvertently acted as a quality auditor, highlighting unsuspected inconsistencies:
- obsolescence of references: the AI correctly rejected reports based on URLs that were no longer up to date in our program descriptions.
- data technical debt: the lack of formal links between certain old duplicates complicated validation, as the AI detected correlations invisible in the structured history.
- human errors and contextual nuances: we found past reports that were poorly qualified, but also cases where the human decision deviated from the business rule for pragmatic reasons or exceptional processes (which the AI, being strict by nature, could not anticipate).
Technically, the exercise tested our infrastructure, notably the load limits of n8n when processing 300 reports simultaneously. This constraint forced us to optimize the execution of our agents.
With the POC phase demonstrating the value of the use case, we have now entered a beta test phase to define the conditions for an industrialized deployment to end users.
This POC also identified necessary improvements for the next phase, such as:
- better presentation of the AI analysis results.
- injecting client context to refine AI agent analysis.
- implementing RAG (Retrieval-Augmented Generation) to aid duplicate detection.
- revisiting the CVSS workflow to achieve automated and reliable severity estimation.
This is just the beginning of a smarter triage, where AI doesn’t replace the expert but offers a healthier and faster basis for decision-making.






