

Table of Contents
At Yogosha, Offensive Security Platform, we questioned what AI applied to offensive security truly means. We therefore decided to explore the subject to try to answer several key questions:
- What do the concepts we regularly see encompass: LLM, Agent, Agentic AI, Context window, MCP, Token, ReAct, etc.?
- What could the future of offensive security look like, as more and more players offer AI-based tools (Xbow, CAI, and others)?
- How can an agentic offensive tool be built?
In order to explore these questions, we developed —modestly— a Proof of Concept (PoC) of an automated offensive tool based on an agentic approach, where the AI no longer simply responds to instructions, but takes decisions, acts autonomously, and adapts its behavior according to what is happening.
Transposing hacker methodology into agent workflows
Rather than inventing a new paradigm, we started from a simple observation: a hacker almost always follows the same cycle:
Reconnaissance → Analysis → Attack → Analysis → Reporting → Iteration
Our PoC therefore aims to formalize this human reasoning in the form of specialized agents, capable of collaborating within the same system.
Objectives and scope of the Proof of Concept
The PoC must meet four clear functional objectives :
- Retrieve a security program (Bug Bounty, Pentest, VDP): A security program allows an organization to define targets to be audited — corresponding to a perimeter of its assets — by ethical hackers, within a legal framework, in order to identify vulnerabilities.
- Perform a reconnaissance phase on the program’s target to identify attack surfaces and potential weaknesses.
- Perform an attack phase on the program’s target to detect potential vulnerabilities.
- Report vulnerabilities to a Yogosha security program.
Assumed Constraints:
- Target : Web Assets only.
- Vulnerabilities: A reduced scope. As this is a PoC, the goal is not to cover everything, but to focus on a few types of vulnerabilities to understand the complexity of the subject (Broken Access Control, Stored XSS, Server-Side Vulnerability, Sensitive data exposure, Security misconfigurations).
- Rate limiting is not taken into account for this PoC, as it is conducted on targets previously identified as load-tolerant.
- The offensive tool takes the form of an entirely automated workflow, requiring no human intervention, except for target validation.
Architecture of an agent-driven offensive tool
The architecture of our offensive project relies on an agentic approach, in which each agent is specialized in a specific task and operates within a dedicated team.
The system is divided into three teams of agents :
- Reconnaissance Team → Target mapping (network, endpoints, technologies, functional mapping).
- Attack Team → Detection and validation of vulnerabilities (see list of covered vulnerabilities).
- Reporting Team → Generation and publication of the security report.

Exposing offensive capabilities to agents
Transforming offensive reasoning into concrete actions requires connecting LLMs to reliable technical tools.
This section presents the AI stack and the architecture implemented to expose offensive capabilities via dedicated MCP servers, with strong guarantees of isolation, control, and security.
AI Layer
The AI layer is deployed internally and connected to our VLLM. It exposes an API that agents use to send their prompts and receive responses, while keeping data and processing entirely confined to our infrastructure.
Tools
Before exposing the various tools, it is necessary to briefly introduce the concept of MCP (Model Context Protocol).
MCP is an open-source standard that allows AI applications (and therefore LLMs) to connect to external systems.
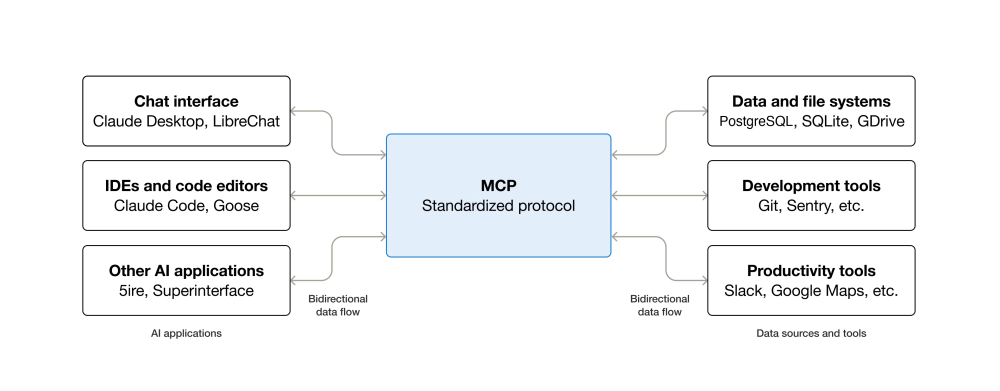
An MCP server therefore exposes Tools that can be called by LLMs. These tools allow for interaction with external systems (querying databases, performing product actions, etc.).
Yogosha Application (via MCP Server): Exposes the main functionalities of the Yogosha application so that LLMs can use them directly (report creation, security program retrieval, etc.).
Offensif tools (via Serveur MCP): We have implemented a dedicated Offensive MCP server, designed to expose a set of tools that LLMs can invoke directly, without weighing down the main framework.
This architecture offers several advantages :
- Scalability: simple addition of new offensive tools without modifying the core of the system.
- Isolation & encapsulation: each offensive tool is exposed via a dedicated MCP tool, offering enhanced control.
- Traceability & governance: encapsulation allows for better auditing of the use of these sensitive tools, which is essential when they are made available to an LLM.

The server is a standalone PHP CLI binary, built with the php-mcp/server libraries and the symfony/process component.
The exposed Tools are the following :
- Ffuf to discover the target’s endpoints.
- Specific web wordlists from SecLists
- Nmap to identify exposed services.
- Nuclei to detect custom vulnerabilities.
- Web application detector to detect technologies.
Web Explorer (via MCP Server)
The Web Explorer MCP server exposes Playwright, a browser automation tool, allowing the LLM to control a web application in order to perform reconnaissance, functional mapping, and the validation of flaws requiring real interaction with the application.
Custom Tools:
- HTTP Request Tool — Allows for sending fully customized requests (method, path, headers, request body) in order to explore application behavior and test offensive payloads.
- Web Extraction Tool — Automates the collection of web content to facilitate reconnaissance, application mapping, and the retrieval of relevant information.
Offensive iterations: the agent progression engine
How can an agentic offensive tool be evolved to actually detect vulnerabilities? By iterating — but not blindly.
In its design phase, an offensive pipeline fails in the majority of cases: misunderstood attack surface, erroneous hypotheses, unsuitable exploitation, misuse of tools, false positives, lack of a tool, etc.
These failures are not errors to be hidden, but signals to be exploited.
The core of the system relies on the repetition of an offensive loop guided by failure :
Reconnaissance → Attack → Critical analysis of results → Targeted adjustment of reasoning, tools, or hypotheses → New iteration.

Each iteration does not restart from scratch: it builds on the information acquired to reduce the uncertainty and refine the offensive strategy.
To evaluate the system’s progression, we work on targets with known vulnerabilities. This allows us to compare results from one iteration to another, to verify that changes made to the pipeline produce a real effect, and to avoid confusing effective improvement with mere chance.
Designing robust and specialized agents
Agent Template
To obtain the most reliable offensive pipeline possible, each agent must be simple, specialized, and testable. We have therefore structured our system around several core principles.
- Team-based partitioning to compartmentalize responsibilities.
- Clear and isolated roles for our agents (e.g., Network Recon Agent, Stored XSS Agent, etc.).
- 1–2 tools per agent – Limits prompt complexity and side effects (context window, tool misuse, etc.).
- Code-first preference: If a task can be performed reliably by code or automation, prioritize the programmatic solution over the LLM.
- Agent Prompt Structure
- User Input > Objective, Data
- System Context > Context (agent specialization), Role, Methodology, Security and Compliance, Detailed Actions.
Agent Evaluation
Special attention is paid to the evaluation of agent results. The goal is to ensure reliability: each agent must produce a stable and testable output.
Criteria favoring effective evaluation :
- Strict and testable output (Normalized JSON / JSON Schema) to standardize results.
- Normalization of results with strict instructions to prevent large language model hallucinations.
- Automated evaluations: Unit assertions on results (e.g. a Network Recon agent must find a specific set of open ports and detected services on a known target).
From reconnaissance to exploitation: orchestrating an automated attack
Before testing our agents on real—and therefore more complex—applications, we needed a controlled, reproducible, and well-documented experimental ground.
This naturally led us to crAPI, an open-source vulnerable application widely used for learning and evaluating application security techniques. In our approach, crAPI serves as an offensive sandbox, ideal for measuring an agent’s progress and refining the tools.
Custom XSS vulnerabilities were intentionally added to crAPI in order to increase the number of exploitation scenarios for our agents.
Retrieving a security program
Before starting, the first step consists of retrieving a security program whose target corresponds to crAPI. This operation is performed via our MCP server. The Yogosha MCP server exposes the get_a_program tool, which allows for the retrieval of a security program (pentest, bug bounty, VDP).
The agent will therefore retrieve the given program, ensure that it is indeed open and accessible to the user triggering the workflow, and then format a result that will be used by the other agents.

{
"id": "UUID",
"name": "Crapi API",
"state": "online",
"scope": [
"crAPI"
],
"asset": {
"type": "api"
}
}
Reconnaissance Phase
Once the target is identified, the reconnaissance phase is broken down into four steps :
- Network Reconnaissance (Network Analyst Agent)
- Technology Reconnaissance (Technologies Analyst Agent)
- Fuzzing Reconnaissance (Fuzzing Analyst Agent)
- Functional Reconnaissance (Product Analyst Agent)
We won’t detail every block, but rather zoom in on two agents: Fuzzing Analyst & Product Analyst, as they best illustrate the capabilities of an LLM coupled with the right tools and prompts.
Product Analyst Agent
The objective of this agent is to provide a product analysis of the target to other agents/teams. To perform this reconnaissance, it uses our Web Explorer MCP server, which allows it to interact with a browser.

The LLM receives a user prompt asking it to explore the target:
Explore the website: {{ TARGET }}
Credentials:
{{ CREDENTIALS }}
The methodology integrated into the system prompt breaks this task into several steps:
- Manage the authentication phase.
- Identify and produce a mapping of the 10 main features.
# SYSTEM
You are a Playwright Explorer agent.
## Rules
1. Navigate to the website.
2. Take a snapshot of the page.
3. Use the credentials given by the user to authenticate if needed.
4. Analyse the page to identify the main product features (Max 10 main features / Dont hesitate navigate on differents pages).
5. For each feature, describe where it can be found (e.g., main menu, hero section, cards section, footer), the detailed product intention and the trace (http endpoints call)
## OUTPUT
Return a JSON array of potential main product features
Result normalization by the LLM
[
{
"feature": "Vehicle Details",
"description": "Shows the registered vehicle's information (VIN, model, fuel type, year) and provides quick actions such as Service History, Contact Mechanic and Refresh Location.",
"location": "Dashboard → Vehicles Details card",
"trace": [
"GET <https://CRAPI/identity/api/v2/vehicle/vehicles>"
]
},
{
"feature": "Vehicle Service History",
"description": "Displays a chronological list of all service events for the selected vehicle.",
"location": "Dashboard → Vehicles Details card → \\"Vehicle Service History\\" button",
"trace": [
"GET <https://CRAPI/identity/api/v2/vehicle/service_history>"
]
},
{
"feature": "Contact Mechanic",
"description": "Opens a form or triggers a request to connect the user with a qualified mechanic for the vehicle.",
"location": "Dashboard → Vehicles Details card → \\"Contact Mechanic\\" button",
"trace": [
"GET <https://CRAPI/identity/api/v2/vehicle/contact_mechanic>"
]
},
...
]
Use Cases
- Provide more precise context to the reconnaissance report.
- Validate the exploitability of an XSS flaw: a dedicated agent can rely on elements from the reconnaissance report to quickly identify relevant interface areas to test.
- Generate wordlists for endpoint fuzzing based on product-specific terms.
Fuzzing Analyst Agent
The objective of this agent is to produce a list of validated endpoints, directly exploitable by the Attack Team and integrated into the final report.
In the reconnaissance phase, fuzzing constitutes a key step for effectively mapping the exposed surface by revealing accessible endpoints that are not explicitly documented.

Tools :
- ffuf (via Offensive MCP) Fuzzing of the API/web surface with dedicated wordlists. Detected generic paths (/api/, /v1/, etc.) trigger recursive fuzzing if the LLM deems it relevant.

- Custom Scraper Path extraction from HTML and JavaScript. Results are merged, deduplicated, and then validated via OPTIONS requests.
Current limits on the Recon part
- Verbosity of certain tools.
- Context window limits and the resulting token costs.
- Complexity during the authentication phase with the Product Recon agent.
- Lack of an offensive scenario involving endpoint chaining.
Once the reconnaissance phase is complete, the collected information is consolidated into a reconnaissance report and transmitted to the offensive team, serving as the entry point for the attack phase.
Attack Phase
In the context of this PoC, the attack scope is intentionally reduced. It consists of three steps:
- Web Server Agent Identifies server-side vulnerabilities, including the web server, the application stack, the framework, and exposed configurations.
- Exposure Discovery Agent Identifies endpoints accessible without authentication and data leaks resulting from missing or insufficient access control.
- Stored XSS Agent Identifies Stored XSS by injecting payloads and verifying that they are stored and then rendered by the application.
As with the reconnaissance part, we will focus on two agents from the attack phase to more concretely illustrate the capabilities of an LLM coupled with suitable tools and a targeted prompt.
Web Server Agent
The objective of this agent is to find vulnerabilities related to the server, frameworks, and languages.

It relies on the reconnaissance report produced upstream and uses two tools:
- Nuclei (via the offensive MCP server) Delivered by our offensive MCP server with about fifty tags at its disposal (ssl, nginx, etc.). The choice of tags is made by the LLM based on its interpretation of the reconnaissance report.

- HTTP Request Tool Used to query vulnerability databases and identify potential CVEs associated with the detected versions.
Final result normalization by the LLM.
[
{
"endpoint": "<https://13.39.155.241:8443>",
"description": "Missing **Content‑Security‑Policy (CSP)** header. CSP is a powerful mitigation against cross‑site scripting (XSS), data injection, and clickjacking by restricting the sources from which content can be loaded. Without CSP, the application is vulnerable to injection of malicious scripts through any of its 46 discovered API endpoints, which could lead to credential theft, session hijacking, or arbitrary code execution in the victim's browser. Severity: high.",
"severity": "low"
},
{
"endpoint": "<https://13.39.155.241:8443>",
"description": "Missing **Strict‑Transport‑Security (HSTS)** header. HSTS forces browsers to interact with the site only over HTTPS, preventing protocol‑downgrade attacks and cookie stripping. Without HSTS, an attacker can force a user to connect over HTTP, enabling man‑in‑the‑middle interception of authentication tokens or API calls. Severity: high.",
"severity": "high"
},
{
"endpoint": "<https://13.39.155.241:8443>",
"description": "Self‑signed TLS certificate. The server presents a self‑signed X.509 certificate that is not trusted by browsers and expires in 2035. This enables man‑in‑the‑middle attackers to present a fraudulent certificate without triggering browser warnings if the user manually trusts it, facilitating decryption of all traffic and credential theft. Severity: low.",
"severity": "low"
},
...
]
Stored XSS Agent
The objective of this agent is to inject XSS payloads and verify that they are persisted by the application. It relies on a list of candidate XSS endpoints (pre-filtered) as well as the reconnaissance report produced upstream.
When an XSS payload is persisted, the agent marks the endpoint as potentially vulnerable and delegates exploitability validation to an XSS Validator Agent.
This sub-agent targets only the pages and flows likely to render the persisted content, based on functional reconnaissance and the endpoint’s structure, without crawling the entire application.

The following diagram illustrates how the Stored XSS Agent utilizes a ReAct loop to test candidate endpoints using the XSS Query Tool.

Final result normalization by the LLM
[
{
"vulnerabiliy": [
{
"endpoint": "<https://CRAPI/community/api/v2/community/posts>",
"vulnerability": "The POST /community/api/v2/community/posts endpoint stores user‑supplied content in the `content` field. Multiple stored XSS payloads were submitted (plain <script>, <img onerror>, and URL‑encoded script). In all cases, the backend returns the persisted content with HTML entity encoding (e.g., `<` → `<`, `>` → `>`, quotes → `'`), indicating that server‑side output escaping is correctly applied and prevents script execution at the API level. However, the presence of persisted user‑controlled content confirms that this endpoint acts as a stored content vector. While the tested payloads are not directly exploitable through the API response, such vectors remain sensitive and may become exploitable if the content is later rendered in an unsafe context on the client side (e.g., DOM‑based rendering, decoding, or unsafe HTML injection). Manual validation is therefore required to assess real‑world exploitability in the frontend rendering layer."
,
"vulnerability_validation": "During frontend validation, the persisted payload injected via the API endpoint <https://CRAPI/community/api/v2/community/posts> is rendered in the Community section using an unsafe DOM rendering context. Although the backend correctly escaped the stored content, the frontend re‑injects it in a way that allows HTML interpretation, resulting in a stored DOM‑based XSS. The payload successfully triggers an `alert('agent_xss_stored')`, confirming that arbitrary JavaScript execution is possible in the context of an authenticated user."
}
]
}
]
The vulnerability_validation part was added by the XSS Validator Agent. The latter navigated the target to validate whether the XSS flaw is exploitable.
Once the offensive agents have reported a set of potential vulnerabilities, the Lead Agent, responsible for coordinating the entire system, enters an analysis phase.
Its role is to detect duplicates and normalize the results in order to produce a consolidated view of the identified vulnerabilities.
Once this phase is completed, the normalized list of vulnerabilities is transmitted to the Reporting Team, which is responsible for generating the security reports.
Building a Security Report
The team analyzes each vulnerability to produce actionable security reports on the Yogosha platform.
The agent in charge of creating security reports has the following missions :
- Define a clear and explicit title for the vulnerability report;
- Identify and classify the vulnerability type (XSS, Broken Access Control, etc.);
- Propose an appropriate remediation, contextualized to the audited application.

Conclusion
This Proof of Concept allowed us to concretely explore the potential, as well as the limits, of offensive tools based on an agentic approach.
Within the scope covered by our agents, the tests conducted on crAPI identified several types of vulnerabilities:
- Stored XSS
- Sensitive Data Exposure
- Broken Access Control
- Information Disclosure
- Security Misconfiguration
- Cryptographic Misconfiguration
At the same time, certain classes of vulnerabilities were not detected. This observation is not due to an intrinsic limit of the approach, but primarily to the absence of specialized agents for those specific categories. A truly effective agentic offensive tool relies on a constellation of specialized agents, each with a clear role, a mastered prompt, and adapted tools. The quality of the results depends directly on this specialization.
For our PoC, three areas of improvement currently appear essential:
- Deploying one agent per vulnerability type, to increase coverage and depth of analysis.
- Introducing asynchronous vulnerability management, allowing a flaw to be submitted as soon as it is detected without waiting for the end of the workflow.
- Building true offensive scenarios starting from the reconnaissance phase, to enable stateful fuzzing and more realistic action chaining.
Rather than a ready-to-use tool, this PoC highlights a reality: offensive AI is primarily an engineering and methodology challenge, where agentic design, orchestration, and specialization matter far more than the LLM itself.






