

Table of Contents
Comprendre et anticiper l’impact des outils offensifs basés sur l’IA dans le domaine de la cybersécurité.
Chez Yogosha, plateforme de sécurité offensive, nous nous sommes interrogés sur ce que signifie réellement l’IA appliquée à la sécurité offensive. Nous avons donc décidé d’explorer le sujet pour tenter de répondre à plusieurs questions clés :
- Que recouvrent les concepts que l’on voit passer régulièrement : LLM, Agent, Agentic AI, Context window, MCP, Token, ReAct, etc. ?
- À quoi pourrait ressembler l’avenir de la sécurité offensive, à mesure que de plus en plus d’acteurs proposent des outils basés sur l’IA (Xbow, CAI, et d’autres) ?
- Comment peut se construire un outil offensif agentique ?
Afin d’explorer ces questions, nous avons développé —modestement— un Proof of Concept (PoC) d’un outil offensif automatisé reposant sur une approche agentique, où l’IA ne se contente plus de répondre à des instructions, mais prend des décisions, agit de manière autonome et adapte son comportement en fonction de ce qui se passe.
Transposer la méthodologie du hacker en workflow d’agents
Plutôt que d’inventer un nouveau paradigme, nous sommes partis d’un constat simple, un hacker suit presque toujours le même cycle :
Reconnaissance → Analyse → Attaque → Analyse → Reporting → Itération
Notre PoC vise donc à formaliser ce raisonnement humain sous forme d’agents spécialisés, capables de collaborer au sein d’un même système.
Objectifs et périmètre du Proof of Concept
Le PoC doit répondre à quatre objectifs fonctionnels clairs
- Récupérer un programme de sécurité (Bugbounty, Pentest, VDP) Un programme de sécurité permet à une organisation de définir des cibles à auditer — correspondant à un périmètre de ses assets — par des hackers éthiques, dans un cadre légal, afin d’identifier des vulnérabilités.
- Effectuer une phase de reconnaissance sur la cible du programme afin d’identifier des surfaces d’attaque et des faiblesses potentielles.
- Effectuer une phase d’attaque sur la cible du programme afin de détecter de potentielles vulnérabilités.
- Reporter des vulnérabilités sur un programme de sécurité Yogosha.
Contraintes assumées
- Cible : uniquement des Assets Web
- Vulnérabilités : un périmètre réduit PoC oblige : l’objectif n’est pas de tout couvrir, mais de se concentrer sur quelques types de vulnérabilité pour comprendre la complexité du sujet (Broken Access Control, Stored Xss, Server‑Side Vulnerability, Sensitive data exposure, Security misconfigurations).
- Non prise en compte du rate limit pour ce PoC sur cibles préalablement identifiées comme tolérantes à la charge.
- L’outil offensif prend la forme d’un workflow entièrement automatisé, ne nécessitant aucune intervention humaine, hormis la validation de la cible.
Architecture d’un outil offensif piloté par agents
L’architecture de notre projet offensif repose sur une approche agentique, dans laquelle chaque agent est spécialisé dans une tâche précise et opère au sein d’une équipe dédiée.
Le système est découpé en trois équipes d’agents :
- Équipe de reconnaissance → Cartographie de la cible (réseau, endpoints, technologies, cartographie fonctionnelle)
- Équipe d’attaque → Détection et validation des vulnérabilités (voir liste des vulnérabilités couvertes).
- Équipe de reporting → Génération et publication du rapport de sécurité

Exposer des capacités offensives aux agents
Transformer un raisonnement offensif en actions concrètes nécessite de connecter les LLM à des outils techniques fiables.
Cette section présente la brique IA et l’architecture mise en place pour exposer des capacités offensives via des serveurs MCP dédiés, avec des garanties fortes d’isolation, de contrôle et de sécurité.
AI Layer
La couche IA est déployée en interne et connectée à notre VLLM. Elle expose une API que les agents utilisent pour envoyer leurs prompts et recevoir les réponses, tout en gardant données et traitement entièrement confinés à notre infrastructure.
Tools
Avant d’exposer les différents outils ****il est nécessaire d’introduire brièvement le concept de MCP (Model Context Protocol).
MCP est une norme open source qui permet de connecter des applications IA (& donc des LLM) à des systèmes externes.
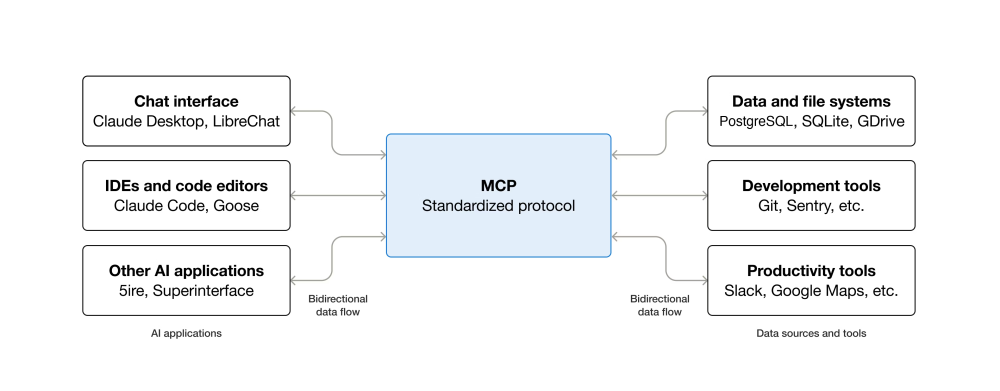
Un serveur MCP va donc exposer des Tools qui peuvent être appelés par les LLM. Ces outils permettent d’interagir avec des systèmes externes (interroger des bases de données, effectuer des actions produits, etc.)
Application Yogosha (via Serveur MCP)
Expose les fonctionnalités principales de l’application Yogosha afin que les LLM puissent les utiliser directement (création de rapport, récupération d’un programme de sécurité, etc.)
Offensif tools (via Serveur MCP)
Nous avons mis en place un serveur MCP Offensif dédié, conçu pour exposer un ensemble d’outils que les LLM peuvent invoquer directement, sans alourdir le framework principal.
Cette architecture présente plusieurs avantages :
- Scalabilité : ajout simple de nouveaux tools offensifs sans modifier le cœur du système.
- Isolation & encapsulation : chaque outil offensif est exposé via un tool MCP dédié, offrant un contrôle renforcé.
- Traçabilité & gouvernance : l’encapsulation permet de mieux auditer l’usage de ces outils sensibles, ce qui est essentiel lorsqu’ils sont mis à disposition d’un LLM.

Le serveur est un binaire CLI PHP autonome, construit avec les librairies php-mcp/server et le composant symfony symfony/process
Les Tools exposés sont les suivants :
- Ffuf pour découvrir les endpoints de la cible.
- Certaines wordlist web de SecLists.
- Nmap pour identifier les services exposés.
- Nuclei pour détecter des vulnérabilités custom.
- Web application detector pour détecter les technologies.
Web Explorateur (via Serveur MCP)
Le serveur MCP Web Explorateur expose Playwright, un outil d’automatisation de navigateur, permettant au LLM de contrôler une application web afin de réaliser la reconnaissance, une cartographie des fonctionnalités et la validation de failles nécessitant une interaction réelle avec l’application.
Outils personnalisés
- Outil de requêtes HTTP — Permet d’envoyer des requêtes entièrement personnalisées (méthode, chemin, en-têtes, corps de requête) afin d’explorer le comportement applicatif et de tester des charges offensives.
- Outil d’extraction web — Automatise la collecte de contenu web pour faciliter la reconnaissance, la cartographie de l’application et la récupération d’informations pertinentes.
Itérations offensives : le moteur de progression des agents
Comment faire évoluer un outil offensif agentique pour qu’il détecte réellement des vulnérabilités ?
En itérant — mais pas aveuglément.
Dans sa phase de conception, une pipeline offensive échoue dans la majorité des cas : surface mal comprise, hypothèses erronées, exploitation inadaptée, mauvaise utilisation des outils, faux positifs, manque d’un outil, etc.
Ces échecs ne sont pas des erreurs à masquer, mais des signaux à exploiter.
Le cœur du système repose sur la répétition d’une boucle offensive guidée par l’échec :
reconnaissance → attaque → analyse critique des résultats → ajustement ciblé du raisonnement, des outils ou des hypothèses → nouvelle itération.

Chaque itération ne redémarre pas de zéro : elle s’appuie sur les informations acquises pour réduire l’incertitude et affiner la stratégie offensive.
Pour évaluer la progression du système, nous travaillons sur des cibles dont les vulnérabilités sont connues. Cela permet de comparer les résultats d’une itération à l’autre, de vérifier que les changements apportés au pipeline produisent un effet réel, et d’éviter de confondre amélioration effective et simple hasard.
Concevoir des agents robustes et spécialisés
Template d’un agent
Pour obtenir une pipeline offensive la plus fiable possible, chaque agent doit être simple, spécialisé et testable. Nous avons donc structuré notre système autour de plusieurs principes forts.
- Découpage par équipe afin de compartimenter les responsabilités.
- Nos agents ont un rôle clair et isolé (ex : Agent Network Recon, Agent Stored XSS, etc.)
- 1–2 outils par agent – Limite la complexité du prompt et les effets de bords (context window, mauvaise utilisation d’un tool, etc.)
- Si une tâche peut être faite de façon fiable par du code ou une automatisation, privilégier la solution programmatique plutôt que le LLM.
- Structure du prompt d’un agent
- Entrée utilisateur > Objectif, Données
- Contexte système > Contexte (spécialisation de l’agent), Rôle, Méthodologie, Sécurité et conformité, Actions détaillées
Evaluation d’un agent
Une attention particulière est portée sur l’évaluation des résultats des agents. L’objectif est de fiabiliser : chaque agent doit produire un résultat stable et testable.
Critères favorisant une bonne évaluation :
- Output strict et testable (JSON normalisé / JSON Schema) pour standardiser les résultats.
- Normalisation des résultats avec une instruction stricte pour éviter les hallucinations du modèle de langage.
- Évaluations automatisées : assertions unitaires sur les résultats (ex : un agent de Network Recon doit retrouver un ensemble de ports ouverts et services détectés sur une cible connue).
De la reconnaissance à l’exploitation : orchestration d’une attaque automatisée
Avant de tester nos agents sur des applications réelles —et donc plus complexes— nous avions besoin d’un terrain d’expérimentation contrôlé, reproductible, et déjà bien documenté.
C’est ce qui nous a naturellement conduits vers crAPI, une application vulnérable open-source largement utilisée pour l’apprentissage et l’évaluation des techniques de sécurité applicative. Dans notre démarche, crAPI joue le rôle d’un bac à sable offensif, idéal pour mesurer la progression d’un agent et affiner les outils.
Des vulnérabilités XSS ont été volontairement ajoutées à crAPI afin de multiplier les scénarios d’exploitation pour nos agents.
Récupérer un programme de sécurité
Avant de commencer, la première étape consiste à récupérer un programme de sécurité dont la cible correspond à crAPI. Cette opération passe par notre serveur MCP. Le serveur MCP Yogosha expose le tool get_a_program qui permet de récupérer un program de sécurité (pentest, bugbounty, VDP).
L’agent va donc récupérer le programme donné, s’assurer qu’il est bien ouvert et accessible pour l’utilisateur qui déclenche le workflow, puis formater un résultat qui sera utilisé par les autres agents.nts.

{
"id": "UUID",
"name": "Crapi API",
"state": "online",
"scope": [
"crAPI"
],
"asset": {
"type": "api"
}
}
Phase de reconnaissance
Une fois la cible identifiée, la phase de reconnaissance se décline en quatre étapes :
- Reconnaissance réseau (Agent Network Analyst)
- Reconnaissance des technologies (Agent Technologies Analyst)
- Reconnaissance par fuzzing (Agent Fuzzing Analyst)
- Reconnaissance fonctionnelle (Agent Product Analyst)
Nous n’allons pas détailler chaque brique, mais zoomer sur deux agents : Fuzzing Analyst & Product Analyst, car ils permettent de mieux illustrer les capacités d’un LLM couplé aux bons tools et au bon prompt.
Agent Product Analyst
L’objectif de cet agent est de fournir une analyse produit de la cible aux autres agents / équipes.
Pour réaliser cette reconnaissance il utilise notre serveur MCP Web Explorateur qui permet d’interagir avec un navigateur.

Le LLM va recevoir le prompt user qui lui demande d’explorer la cible.
Explore the website: {{ TARGET }}
Credentials:
{{ CREDENTIALS }}
La méthodologie intégrée dans le prompt system découpe cette tâche en différentes étapes :
- Gérer la phase d’authentification
- Identifier et produire une cartographie des 10 principales fonctionnalités
# SYSTEM
You are a Playwright Explorer agent.
## Rules
1. Navigate to the website.
2. Take a snapshot of the page.
3. Use the credentials given by the user to authenticate if needed.
4. Analyse the page to identify the main product features (Max 10 main features / Dont hesitate navigate on differents pages).
5. For each feature, describe where it can be found (e.g., main menu, hero section, cards section, footer), the detailed product intention and the trace (http endpoints call)
## OUTPUT
Return a JSON array of potential main product features
Normalisation du résultat par le LLM
[
{
"feature": "Vehicle Details",
"description": "Shows the registered vehicle's information (VIN, model, fuel type, year) and provides quick actions such as Service History, Contact Mechanic and Refresh Location.",
"location": "Dashboard → Vehicles Details card",
"trace": [
"GET <https://CRAPI/identity/api/v2/vehicle/vehicles>"
]
},
{
"feature": "Vehicle Service History",
"description": "Displays a chronological list of all service events for the selected vehicle.",
"location": "Dashboard → Vehicles Details card → \\"Vehicle Service History\\" button",
"trace": [
"GET <https://CRAPI/identity/api/v2/vehicle/service_history>"
]
},
{
"feature": "Contact Mechanic",
"description": "Opens a form or triggers a request to connect the user with a qualified mechanic for the vehicle.",
"location": "Dashboard → Vehicles Details card → \\"Contact Mechanic\\" button",
"trace": [
"GET <https://CRAPI/identity/api/v2/vehicle/contact_mechanic>"
]
},
...
]
Cas d’usage
- Apporter un contexte plus précis au rapport de reconnaissance
- Valider l’exploitabilité d’une faille XSS : un agent dédié peut s’appuyer sur les éléments du rapport de reconnaissance pour identifier rapidement les zones de l’interface pertinentes à tester.
- Générer des wordlist pour du fuzzing de endpoint en se basant sur des termes produit.
Agent Fuzzing Analyst
L’objectif de cet agent est de produire une liste d’endpoints validés, directement exploitable par la Team Attack et intégrée au rapport final.
Dans la phase de reconnaissance, le fuzzing constitue une étape clé pour cartographier efficacement la surface exposée, en révélant des endpoints accessibles mais non explicitement documentés.

Tools :
- ffuf (via Offensive MCP) Fuzzing de la surface API/web avec des dictionnaires dédiés. Les paths génériques détectés (/api/,/v1/, etc.) déclenchent un fuzzing récursif si le LLM juge cela pertinent.

- Scraper custom Extraction de chemins depuis le HTML et JavaScript. Les résultats sont fusionnés, dédoublonnés, puis validés via des requêtes
OPTIONS.
Limites actuelles sur la partie Recon
- Verbosité de certains tools
- Limite du context window & donc coût en token
- Complexité lors de la phase d’authentification avec l’agent Product Recon
- Manque d’un scénario offensif avec chainage d’endpoints.
Une fois la phase de reconnaissance terminée, les informations collectées sont consolidées dans un rapport de reconnaissance et transmises à l’équipe offensive, servant de point d’entrée à la phase d’attaque.
Phase d’attaque
Dans le cadre de ce PoC, le périmètre d’attaque est volontairement réduit. Il se compose de trois étapes :
- Agent Web Server Identifie des vulnérabilités côté serveur, incluant le serveur web, la stack applicative, le framework et les configurations exposées.
- Agent Exposure Discovery Identifie des endpoints accessibles sans authentification et des fuites de données dues à un contrôle d’accès absent ou insuffisant.
- Agent Stored XSS Identifie des Stored XSS en injectant des payloads et en vérifiant qu’ils sont stockés puis rendus par l’application.
Comme pour la partie reconnaissance, nous allons nous concentrer sur deux agents de la phase d’attaque, afin d’illustrer plus concrètement les capacités d’un LLM couplé à des tools adaptés et à un prompt ciblé.
Agent Web Server
L’objectif de cet agent est de trouver des vulnérabilités liées au serveur, aux frameworks et aux langages.

Il s’appuie sur le rapport de reconnaissance produit en amont et utilise deux tools :
- Nuclei (via le serveur MCP offensif) Délivré par notre serveur mcp offensif avec une cinquantaine de tags mis à sa disposition (ssl, nginx, etc). Les choix des tags sont effectués par le LLM en fonction de l’interprétation qu’il fait du rapport de reconnaissance.

- Outil de requêtes HTTP Utilisé pour interroger des bases de données de vulnérabilités et identifier de potentielles CVE associées aux versions détectées.
Normalisation du résultat final par le LLM.
[
{
"endpoint": "<https://13.39.155.241:8443>",
"description": "Missing **Content‑Security‑Policy (CSP)** header. CSP is a powerful mitigation against cross‑site scripting (XSS), data injection, and clickjacking by restricting the sources from which content can be loaded. Without CSP, the application is vulnerable to injection of malicious scripts through any of its 46 discovered API endpoints, which could lead to credential theft, session hijacking, or arbitrary code execution in the victim's browser. Severity: high.",
"severity": "low"
},
{
"endpoint": "<https://13.39.155.241:8443>",
"description": "Missing **Strict‑Transport‑Security (HSTS)** header. HSTS forces browsers to interact with the site only over HTTPS, preventing protocol‑downgrade attacks and cookie stripping. Without HSTS, an attacker can force a user to connect over HTTP, enabling man‑in‑the‑middle interception of authentication tokens or API calls. Severity: high.",
"severity": "high"
},
{
"endpoint": "<https://13.39.155.241:8443>",
"description": "Self‑signed TLS certificate. The server presents a self‑signed X.509 certificate that is not trusted by browsers and expires in 2035. This enables man‑in‑the‑middle attackers to present a fraudulent certificate without triggering browser warnings if the user manually trusts it, facilitating decryption of all traffic and credential theft. Severity: low.",
"severity": "low"
},
...
]
Agent Stored Xss
L’objectif de cet agent est d’injecter des payloads XSS et de vérifier qu’ils sont persistés par l’application. Il s’appuie sur une liste d’endpoints candidats XSS (pré‑filtrés) ainsi que sur le rapport de reconnaissance produit en amont.
Lorsqu’un payload XSS est persisté, l’agent marque l’endpoint comme potentiellement vulnérable et délègue la validation de l’exploitabilité à un Agent XSS Validator.
Ce sous‑agent cible uniquement les pages et flux susceptibles de rendre le contenu persisté, en s’appuyant sur la reconnaissance fonctionnelle et la structure de l’endpoint, sans parcourir l’ensemble de l’application.

Le schéma suivant permet de visualiser comment l’agent Stored XSS s’appuie sur une boucle ReAct pour tester les endpoints candidats avec le tool XSS Query Tool.

Normalisation du résultat final par le LLM
[
{
"vulnerabiliy": [
{
"endpoint": "<https://CRAPI/community/api/v2/community/posts>",
"vulnerability": "The POST /community/api/v2/community/posts endpoint stores user‑supplied content in the `content` field. Multiple stored XSS payloads were submitted (plain <script>, <img onerror>, and URL‑encoded script). In all cases, the backend returns the persisted content with HTML entity encoding (e.g., `<` → `<`, `>` → `>`, quotes → `'`), indicating that server‑side output escaping is correctly applied and prevents script execution at the API level. However, the presence of persisted user‑controlled content confirms that this endpoint acts as a stored content vector. While the tested payloads are not directly exploitable through the API response, such vectors remain sensitive and may become exploitable if the content is later rendered in an unsafe context on the client side (e.g., DOM‑based rendering, decoding, or unsafe HTML injection). Manual validation is therefore required to assess real‑world exploitability in the frontend rendering layer."
,
"vulnerability_validation": "During frontend validation, the persisted payload injected via the API endpoint <https://CRAPI/community/api/v2/community/posts> is rendered in the Community section using an unsafe DOM rendering context. Although the backend correctly escaped the stored content, the frontend re‑injects it in a way that allows HTML interpretation, resulting in a stored DOM‑based XSS. The payload successfully triggers an `alert('agent_xss_stored')`, confirming that arbitrary JavaScript execution is possible in the context of an authenticated user."
}
]
}
]
La partie vulnerability_validation a été ajoutée par l’agent Xss Validator. Ce dernier a navigué sur la cible afin de valider si la faille xss est exploitable.
Une fois que les agents offensifs ont remonté un ensemble de vulnérabilités potentielles, l’agent Lead, chargé de coordonner l’ensemble du système, entre dans une phase d’analyse.
Son rôle est de détecter les doublons et de normaliser les résultats afin de produire une vue consolidée des vulnérabilités identifiées.
Une fois cette phase terminée, la liste normalisée des vulnérabilités est transmise à l’équipe reporting, responsable de la génération des rapports de sécurité.
Construire un rapport de sécurité
L’équipe analyse chaque vulnérabilité afin de produire des rapports de sécurité exploitables sur la plateforme Yogosha.
L’agent en charge de la création des rapports de sécurité a pour missions :
- définir un titre clair et explicite pour le rapport de vulnérabilité ;
- identifier et classifier le type de vulnérabilité (XSS, Broken Access Control, etc.) ;
- proposer une remédiation adaptée, contextualisée à l’application auditée.

Conclusion
Ce Proof of Concept nous a permis d’explorer concrètement les potentialités, mais aussi les limites, des outils offensifs basés sur une approche agentique.
Sur le périmètre couvert par nos agents, les tests menés sur crAPI ont permis d’identifier plusieurs typologies de vulnérabilités :
- Stored XSS
- Sensitive Data Exposure
- Broken Access Control
- Information Disclosure
- Security Misconfiguration
- Cryptographic Misconfiguration
Dans le même temps, certaines classes de vulnérabilités n’ont pas été détectées. Ce constat n’est pas lié à une limite intrinsèque de l’approche, mais principalement à l’absence d’agents spécialisés pour ces typologies. Un outil offensif agentique réellement efficace repose sur une constellation d’agents spécialisés, chacun avec un rôle clair, un prompt maîtrisé et des outils adaptés. La qualité des résultats dépend directement de cette spécialisation.
Pour notre PoC trois axes d’amélioration apparaissent aujourd’hui comme essentiels :
- disposer d’un agent par type de vulnérabilité, afin d’augmenter la couverture et la profondeur d’analyse ;
- introduire une gestion asynchrone des vulnérabilités, permettant de soumettre une faille dès sa détection sans attendre la fin du workflow ;
- construire de véritables scénarios offensifs dès la phase de reconnaissance, afin de permettre un fuzzing stateful et un chainage plus réaliste des actions.
Plutôt qu’un outil “clé en main”, ce PoC met en évidence une réalité : l’IA offensive est avant tout un problème d’ingénierie et de méthodologie, où la conception agentique, l’orchestration et la spécialisation comptent bien plus que le LLM lui‑même.






