

Table of Contents
Dans le traitement des rapports de vulnérabilités, le triage est une étape charnière. C’est elle qui garantit la qualité des remontées avant qu’elles n’entrent dans le parcours de remédiation. Cependant, c’est aussi une tâche répétitive et chronophage : vérifier le périmètre, identifier les doublons ou valider une sévérité CVSS demande une attention constante, alors même que le volume de rapports ne cesse de croître.
Face à ce défi, nous nous sommes posé une question pragmatique : l’intelligence artificielle peut-elle absorber la charge des tâches à faible valeur ajoutée pour permettre aux analystes de se concentrer sur l’expertise technique complexe ?
C’est l’objectif du Proof of Concept (POC) que nous présentons ici. Loin de vouloir remplacer l’humain, ce projet visait à construire un “assistant de triage” capable de pré-qualifier les soumissions avec fiabilité. Mais pas à n’importe quel prix : la nature critique des données de vulnérabilité nous imposait une contrainte majeure, celle de l’interdiction stricte des LLM publics au profit d’une infrastructure interne et cloisonnée.
Dans cet article, nous détaillons la construction de ce workflow de triage assisté chez Yogosha : du choix d’une architecture articulée autour de n8n et d’agents IA privés, jusqu’aux résultats concrets obtenus sur la détection de rapports en doublons et hors-périmètre.
Solution technique
Choix des outils
Avant même d’implémenter le processus, il fallait définir un cadre technique cohérent avec nos contraintes de sécurité. La règle d’or était simple : aucun LLM public. Les rapports contiennent des informations sensibles et toute l’analyse devait rester strictement hébergée dans notre environnement interne.
La solution devait également permettre :
- d’appeler facilement nos API
- de s’intégrer sans friction avec notre serveur MCP (si besoin)
- de manipuler et transformer des données
- et d’évoluer rapidement selon nos besoins
Nous avons mis plusieurs candidats à l’épreuve :
- n8n, pour sa richesse en connecteurs et sa logique orientée worfklows
- un workflow in-app via la bibliothèque LLPhant, intégrée directement dans la plateforme
- une application externe construite avec CrewAI ou LangChain/LangGraph
Après plusieurs expérimentations, n8n a remporté le match. Il offrait le meilleur compromis : un écosystème de composants très riche, une capacité d’itération rapide, et surtout un système d’évaluation natif permettant de mesurer la qualité des résultats produits.
Une fois la stack choisie, l’étape suivante a été de poser une architecture claire et de voir comment tous les éléments allaient s’articuler ensemble.
Architecture
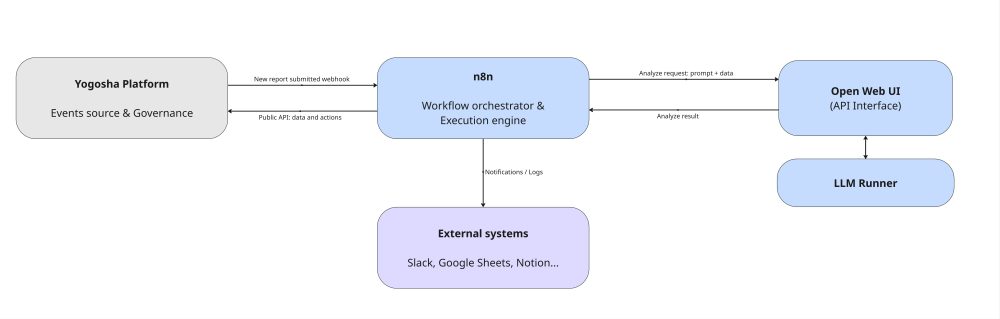
Cette architecture repose sur n8n comme chef d’orchestre. La plateforme Yogosha agit comme source d’événements : lors de la soumission d’un nouveau rapport, elle déclenche un webhook vers n8n qui lance le triage.
Celui-ci pilote ensuite les différentes étapes de traitement, notamment l’appel à l’IA privée Yogosha (exposée via Open WebUI). C’est elle qui analyse les rapports, propulsée par un moteur LLM local.
En parallèle, n8n interagit avec la plateforme Yogosha via son API publique et peut envoyer des résultats vers d’autres systèmes (Slack, Google Spreadsheets, Notion, etc.) grâce à ses nombres intégrations.
L’ensemble permet un flux événementiel clair, découplé et extensible : n8n assure la coordination, la plateforme gère la donnée métier, et l’IA apporte l’intelligence d’analyse.
Workflows
Comme le ferait un triageur humain, notre processus reprend trois étapes clés exécutées successivement.
La première version était un workflow monolithique, un “bloc” unique enchaînant toutes les étapes. Nous avons rapidement vu les limites de cette organisation : impossible de tester automatiquement des parties isolées et chaque modification obligeait à tout re-vérifier.
Nous l’avons donc découpé en plusieurs sous-workflows, plus faciles à maintenir et à fiabiliser.
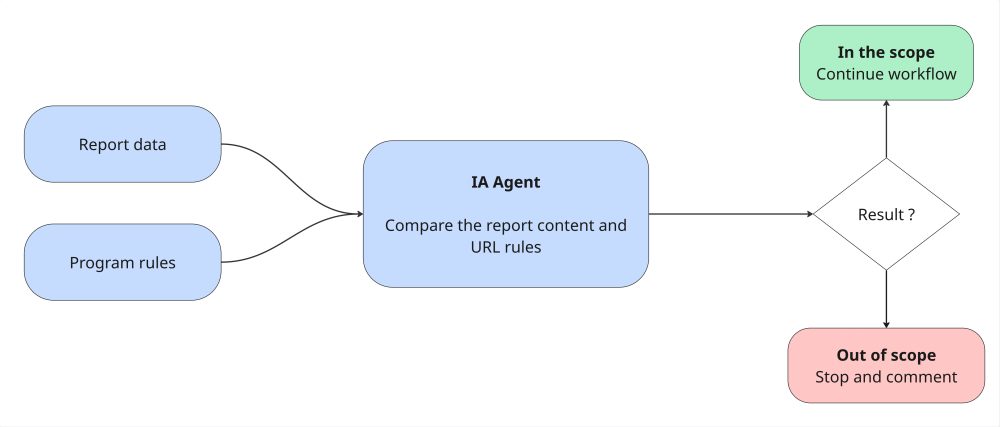
Vérification du périmètre du rapport
Dans cette première étape, nous cherchons à savoir si le rapport soumis correspond bien au périmètre du programme. Pour cela, nous avons mis en place un premier agent IA qui analyse le contenu du rapport (titre, description et preuve du concept) pour les comparer avec les périmètres autorisé et refusé du programme. Cela permet de définir immédiatement si le rapport est légitime ou si nous pouvons en avertir l’utilisateur directement.user directly.
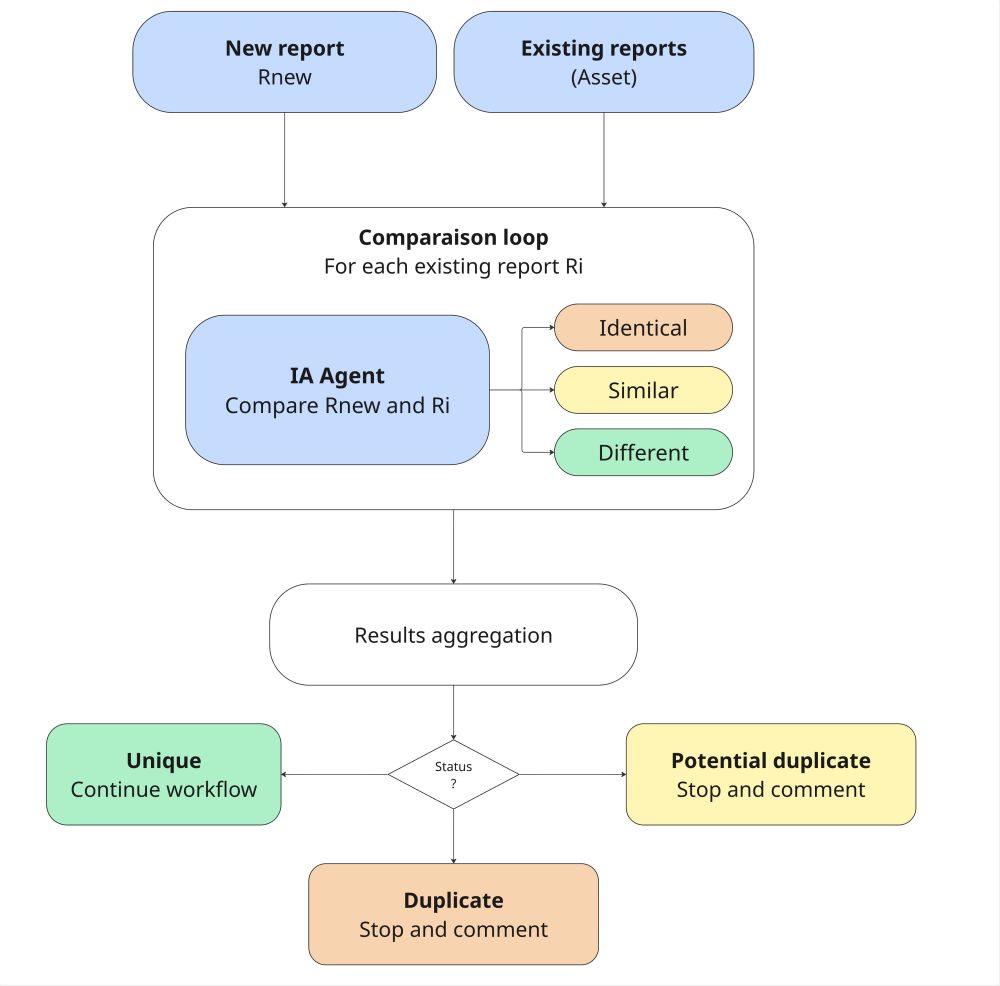
La chasses aux doublons
L’étape suivante consiste à déterminer si un rapport a déjà été soumis pour cette même vulnérabilité. Nous avons défini un agent IA qui compare deux rapports pour définir s’ils sont :
- identiques
- similaires
- sans correspondance
Cette nuance est cruciale pour aider le triageur humain à trancher. En effet, deux rapports sur la même faille mais sur deux ressources différentes (ex : deux endpoints API distincts) peuvent être considérés comme un doublon si le code sous-jacent est commun, ou comme deux bugs distincts. Cet arbitrage dépend souvent du contexte du programme et notre workflow actuel laisse cette décision finale à l’humain.
Concrètement, le workflow récupère les rapports existants sur l’asset concerné et l’IA les compare un à un. Si un doublon (ou doublon potentiel) est détecté, le workflow s’arrête et soumet un commentaire détaillé.
Validation du CVSS
La dernière étape vise à vérifier si le rapport est bien un bug avéré et si le score de sévérité (CVSS) indiqué est pertinent. N’ayant pas réussi à obtenir des résultats à la hauteur de nos exigences de qualité, cette partie du triage a été mise de côté pour se concentrer sur les autres étapes qui permettent d’apporter rapidement de la valeur ajoutée.
Recommandation par l’IA
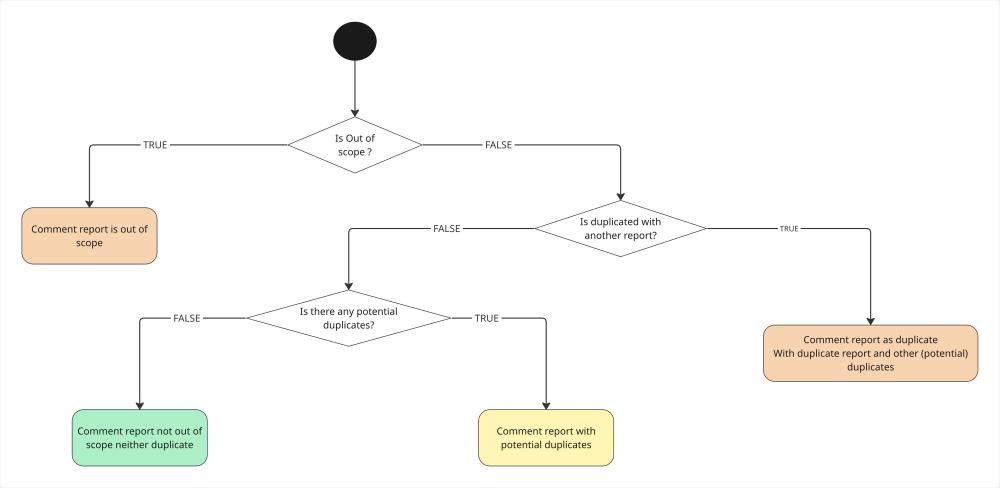
Tout au long du processus de triage, le workflow cherche une raison valide de refuser un rapport pour alerter le triageur.
Si une anomalie est détectée (hors périmètre ou doublon) : un commentaire privé est publié via l’API avec les détails de ces analyses. Il n’est visible que par l’utilisateur triageur.
Si tout est correct : le workflow publie un commentaire pour préciser au client que l’analyse automatisée n’a rien détecté d’anormal.
Le mot de l’équipe Cyber
La vérification manuelle des périmètres et des doublons occupait une part importante de notre temps. Cet outil a permis d’automatiser ces contrôles de base. Désormais, nous pouvons nous consacrer immédiatement à l’expertise technique, avec une prise de décision beaucoup plus rapide et fluide.
Mohamed Foudhaili
Fiabilisation
MCP ou API ?
Dans la toute première version, nous avons tenté d’utiliser le serveur MCP Yogosha pour récupérer les informations nécessaires au triage. Cette approche s’est révélée trop lourde pour l’IA : les définitions d’outils étaient très verbeuses et les réponses (comme les listes de rapports) trop volumineuses, ce qui “noyait” le modèle. En repassant par des appels API classiques, nous avons garanti un comportement déterministe et de bien meilleures performances.
Découpage en sous-workflows
Le découpage modulaire a été salvateur. À l’image de micro-services, cette approche nécessite un effort initial pour définir clairement les entrées et sorties de chaque brique. Mais contrairement au workflow monolithique où tout se mélangeait, ce découpage a clarifié les responsabilités et limité les effets de bord. Surtout, cela a grandement facilité la mise en place d’évaluations.
Validation et fiabilité de l’analyse LLM
L’étape cruciale lors de l’intégration d’un assistant de triage est la validation de la qualité des analyses fournies. Par définition, les agents IA génèrent des résultats non déterministes ; il était donc impératif de mettre en place un mécanisme garantissant la conformité des sorties par rapport à nos attentes.
Pour relever ce défi, nous avons exploité la fonctionnalité “évaluation” de n8n. Cet outil permet d’exécuter un workflow sur un jeu de données spécifique et de confronter les résultats obtenus à une “vérité terrain”.
Nous avons constitué un dataset de plus de 300 rapports réels, issus de nos programmes internes, déjà triés manuellement et clôturés. Le workflow a été exécuté sur cet historique, et ses recommandations ont été comparées automatiquement aux décisions humaines d’origine.
Bien que chronophage, cette démarche itérative s’est avérée indispensable pour mesurer la performance réelle du workflow et visualiser l’impact de chaque modification.
Durant cette première itération, nous avons obtenus ces résultats :
- détection hors périmètre (out of scope) : le workflow identifie 99 % des cas, avec un taux de faux positifs limité à 10 %.
- gestion des doublons : l’IA détecte la présence d’un doublon dans 100 % des cas. En revanche, la précision pour identifier le rapport original spécifique (le “parent”) s’élève à 40 %, ce qui laisse une marge de progression.
Monitoring et Amélioration Continue
Le passage en phase beta ne marque pas la fin du processus, mais le début d’une surveillance active. Pour garantir la pertinence des suggestions sur le long terme, nous avons implémenté une boucle de rétroaction en temps réel.
Concrètement, nous capturons systématiquement chaque interaction pour confronter la recommandation de l’IA à la décision finale de l’expert humain. Ces données alimentent un dashboard de suivi qui nous permet de visualiser :
- la précision globale : un indicateur clé pour mesurer le taux d’alignement entre l’IA et l’humain.
- la performance par catégorie : une analyse granulaire sur la détection des doublons et des rapports hors périmètre.
- l’activité récente : un log des derniers triages pour identifier rapidement les divergences.
Cet outil est indispensable pour piloter la fiabilité de l’assistant et ajuster nos modèles en continu.
Conclusion et key takeaways
Le déploiement de ce premier workflow IA nous a offert bien plus qu’une simple automatisation : il nous a permis de comprendre que la réussite d’un tel projet repose moins sur l’algorithme lui-même que sur la robustesse des frameworks de validation. Ce sont eux qui transforment une intuition technique en un outil fiable, piloté par la donnée.
L’utilisation de données réelles a d’ailleurs révélé un paradoxe intéressant : notre “vérité terrain” (l’historique de nos rapports internes) comportait ses propres biais. Le workflow a agi involontairement comme un auditeur de qualité, mettant en lumière des incohérences insoupçonnées :
- obsolescence des référentiels : l’IA a correctement rejeté des rapports basés sur des URLs qui n’étaient plus à jour dans nos descriptions de programmes.
- dette technique des données : l’absence de liens formels entre certains anciens doublons a complexifié la validation, l’IA détectant des corrélations invisibles dans l’historique structuré.
- erreurs humaines et nuances contextuelles : nous avons relevé des rapports mal qualifiés dans le passé, mais aussi des cas où la décision humaine s’écartait de la règle métier pour des raisons pragmatiques ou relevant de processus exceptionnels (ce que l’IA, par nature stricte, ne pouvait anticiper).
Sur le plan technique, l’exercice a éprouvé notre infrastructure, notamment les limites de montée en charge de n8n lors du traitement simultané de plus de 300 rapports. Cette contrainte nous a forcés à optimiser l’exécution de nos agents.
La phase de POC ayant démontré la valeur du cas d’usage, nous sommes ensuite entrés dans une phase de test beta visant à définir les conditions de déploiement industrialisés auprès des utilisateurs finaux.
Ce POC a également permit d’identifier des pistes d’amélioration nécessaires pour la phase suivant comme :
- une meilleure présentation des résultats de l’analyse de l’IA
- l’injection du contexte client pour affiner l’analyse des agents IA
- la mise en place d’un RAG pour aider à la détection de doublon
- la reprise du workflow sur le CVSS afin d’arriver à une estimation de sévérité automatisée et fiable
Ce n’est que le début d’un triage plus intelligent, où l’IA ne remplace pas l’expert, mais lui offre une base de décision plus saine et plus rapide.






