

Table of Contents
L’IA est partout, on ne parle que de ça ! Dans les entreprises entre la pression du marché, les attentes des commerciaux et l’envie de la direction de ne pas rater le coche, la question n’est plus de savoir s’il faut y aller, mais plutôt comment y aller intelligemment.
Chez Yogosha, Plateforme de Cybersécurité Offensive, nous avons fait le pari fou de la transformation IA en seulement 3 mois et une fois l’impulsion donnée (voir notre article Transformation IA en 3 mois, comment créer le momentum avec l’approche QPQC) et que tout le monde est prêt à avancer dans ce sens, une question très naturelle atterrit sur le bureau des équipes Produit et Tech : « Ok, mais on fait quoi concrètement, et avec quels outils ? »

Passer de l’ambition à la réalisation, c’est là que les choses sérieuses commencent. Il ne suffit plus de vouloir “faire de l’IA”, il faut choisir les bons combats, s’équiper sans se ruiner et monter en compétences sans mettre en péril la sécurité de nos données (ISO 27001 oblige !).
Dans cet article, nous ouvrons le capot pour vous partager notre méthodologie opérationnelle. On va parler de la sélection de nos cas d’usage, de notre infrastructure “maison”, de nos tests flash de 3 jours pour choisir les meilleures technos (nos fameux Spikes) et de la manière dont on a gardé le contrôle sur le budget. Bienvenue dans les coulisses techniques de notre pivot IA.
I. Comment choisir ses cas d’usage ? Le product Management IA
Faire de l’IA, oui, mais, comment s’assurer de faire la bonne IA ?
À l’ère de l’IA, intégrer l’Intelligence Artificielle à son produit est devenu, avouons-le, une nécessité pour rester compétitif. Cette attente est forte chez nos prospects, nos commerciaux, et bien sûr, la direction. Mais avant de plonger, il faut absolument définir quels services IA implémenter et de quelle manière.
La question clé que nous nous sommes posée (et que nous vous encourageons à poser) demeure : Quel problème l’IA peut-elle résoudre de manière significativement meilleure et plus simple que nos approches traditionnelles ?
Étape 1 : Adapter le processus de sélection et de priorisation
Nous avons commencé par une étape simple : lister l’ensemble des problématiques et des cas d’usage potentiels qui nous intéressaient, qu’ils concernent les fonctionnalités de notre plateforme ou l’amélioration de notre productivité interne.
Puis, pour éviter de nous éparpiller, nous nous sommes concentrés sur la priorisation de cette liste en répondant sincèrement aux questions suivantes :
- Un système expert peut-il suffire, ou l’IA est-elle la seule voie possible ?
- Un LLM actuel permet-il déjà d’atteindre le résultat souhaité sans effort supplémentaire ?
- Quel cas d’usage génère réellement le plus de valeur immédiate pour nos utilisateurs ?
Enfin, nous avons complété notre réflexion en analysant les offres de nos concurrents (les autres acteurs du marché de la cybersécurité) et surtout, en approfondissant les principales problématiques et besoins de nos utilisateurs.
Étape 2 : Choisir les deux cas d’usage les plus prometteurs
Notre décision s’est vraiment dessinée après avoir suivi l’évolution d’outils comme Xbow, un ia-pentesteur, et après avoir eu des échanges cruciaux avec un client qui débutait le triage assisté par IA en interne. Ces conversations ont orienté notre choix vers deux cas d’usage majeurs :
1. Le triage assisté par l’IA : le gain de temps
Le triage des rapports de vulnérabilité est une tâche notoirement chronophage. À court terme, nous anticipons une explosion du volume de rapports de sécurité due à la multiplication des outils offensifs dopés à l’IA. Qualifier ces failles rapidement ne sera plus un luxe, mais un enjeu de survie opérationnelle.
C’est ici que nous avons identifié une opportunité majeure : développer une IA capable de détecter les vulnérabilités hors périmètre, les doublons, et de faire une suggestion de triage. Pour nos Security Program Managers, c’est un gain de temps précieux. Pour nos clients, c’est la garantie de pouvoir se concentrer sur l’essentiel — la remédiation — sans être freinés par un manque de ressources ou de compétences en interne pour le tri des rapports.
2. La détection de vulnérabilité et la création d’un rapport : notre ADN offensif
La mission de Yogosha est, par essence, de détecter les vulnérabilités de nos clients afin de sécuriser leurs assets. Il était donc tout à fait naturel d’opter pour un second cas d’usage orienté offensif. Pourquoi ? Parce que nous anticipons que tous les chercheurs s’équiperont d’outils IA dans les mois et années à venir. La capacité de notre IA à détecter des vulnérabilités et à générer un rapport représente pour nous une valeur ajoutée significative et nous ouvre la voie à d’autres opportunités (comme la remontée des résultats des scanners de vulnérabilité).
Notre règle d’or : identifier la problématique
Pour définir vos cas d’usages, voici notre principal conseil : concentrez-vous toujours sur les problématiques business fondamentales que vous souhaitez résoudre. Prenez le temps d’explorer si l’IA est la bonne solution pour améliorer une fonctionnalité, et surtout d’envisager comment la mettre en œuvre de manière sécurisée, éthique et responsable, en définissant clairement les données nécessaires.

💡Si vous ne parvenez pas à formuler clairement la problématique à résoudre et le résultat attendu de la feature IA, il est préférable de s’arrêter : ce n’est pas un cas d’usage pertinent. Développer une feature IA uniquement par obligation ou pour suivre une tendance risque de vous coûter cher en temps et en investissement.
II. Comment choisir ses outils et technologies pour opérer avec l’IA?
Alors, on se lance dans l’IA, mais par où on commence, comment et avec quels outils et techno? C’est forcément la première question à laquelle il a fallu répondre!
Pour y voir clair, notre équipe (Produit et Tech) a avancé ensemble, pas à pas, selon une méthode simple en 4 temps :
- Cadrage : On pose les limites et on définit nos besoins.
- Infra : On construit notre petit labo sécurisé.
- Exploration (Spikes) : On teste les outils à fond, mais rapidement.
- Choix Final : On sélectionne la meilleure solution pour nous.
Étape 1 : Définir les contraintes et les besoins
Avant d’ouvrir la boîte à outils, on a d’abord dû se poser les bonnes questions. C’est une étape cruciale pour éviter de se disperser ou de faire des bêtises !
🔒 Nos deux grosses contraintes (à ne jamais oublier)
Quand on parle d’IA, deux sujets reviennent toujours :
- La Sécurité : Pas question que nos données sensibles se baladent n’importe où sur internet. On devait être en contrôle total.
- Les Coûts : L’IA publique, c’est génial, mais ça facture au token (chaque mot, chaque caractère compte !). Et si on s’en sert beaucoup, l’addition peut vite être salée. Il fallait qu’on maîtrise ce budget.
🤖 Notre grand objectif : Des “Agents Intelligents”
Notre besoin principal était de créer des agents IA qui pourraient prendre en charge des tâches fastidieuses et chronophages.
Ces agents devaient être capables de :
- Travailler avec notre propre IA interne.
- Se connecter à nos systèmes (via notre API ou connecteur MCP sécurisé).
- Nous permettre de tester nos prompts sur différents LLM pour choisir le plus performant, mais aussi de les versionner.
- Nous mettre à disposition des outils mais également nous laisser créer nos propres outils
Étape 2 : Mettre en place un bac à sable IA privé
Pour répondre directement aux contraintes de sécurité et de coûts, l’équipe Infra a eu une idée claire : on va construire notre propre environnement IA privé.
- Le petit laboratoire : l’équipe infra a lancé un POC pour installer une IA privée. Concrètement, on a pris un gros serveur avec une carte graphique puissante (une H100 de 80 Go) et on a chargé différents modèles open source d’IA dessus (merci Ollama.com et Hugging Face !).
- Le calcul gagnant : oui, la machine coûte cher au départ. Mais l’énorme avantage, c’est qu’une fois qu’on a le serveur, on ne consomme plus de tokens ! Fini de payer à la requête. C’est un investissement qui nous donne une sécurité totale et des coûts d’utilisation prévisibles.
- Compter sans payer : l’équipe Infra a même mis en place un outil pour compter tous les tokens que l’on aurait consommés si on était passé par une API publique. Ça nous permet de comparer le coût de notre machine par rapport à la facture salée qu’on aurait reçue autrement !
Le résultat ? On avait notre propre serveur interne sécurisé. Nos deux grosses contraintes étaient gérées !
Étape 3 : Trouver la meilleure techno en 3 jours chrono !
L’environnement est prêt. Maintenant, on choisit quelle techno on va utiliser pour construire nos agents. C’est là que le Spike entre en jeu.
💡 Petit rappel : C’est quoi un “Spike” ?
Si vous faites de l’agilité, vous connaissez sûrement. Le Spike, c’est une étude technique courte et ciblée.
- L’objectif : On veut explorer un sujet flou, mais on ne veut pas y passer des semaines ! C’est time-boxé (on se donne un temps limité) et cadré (on liste les objectifs et les non objectifs de l’étude)
- Le livrable : Une réponse claire qui nous aide à prendre une décision et à réduire le risque avant de se lancer pour de bon.
Le principe ? Mieux vaut tester 3 jours et conclure “ça ne marche pas”, plutôt que de coder pendant 3 semaines pour se rendre compte qu’on fait fausse route.
Dans notre cas précis, cela nous a permis dans un temps investi limité d’acquérir des connaissances nécessaires pour réduire le risque alors qu’on ne savait pas trop où on allait ni comment faire.
🔬 Notre grand test de 3 jours On a sélectionné 4 technologies qui nous semblaient prometteuses (une par développeur volontaire, pas de jaloux !) :
- LangChain / LangGraph
- N8N
- CrewAI
- llphant

L’objectif était simple : chaque techno devait passer au test de nos exigences de l’Étape 1. À la fin des 3 jours, on allait savoir laquelle était la grande gagnante pour nous !
Étape 4 : S’appuyer sur le collectif pour un choix éclairé et adapté
Après ces trois jours intensifs de spikes, l’équipe s’est réunie pour la délibération ! C’était le moment de vérité où chaque développeur a présenté ses découvertes, ses frustrations mais aussi ses succès, et ses conclusions sur la technologie qu’il avait testée.
🔎 Le comparatif des devs
- CrewAI & LangChain / LangGraph : Les poids lourds du Python Ils cochent presque toutes les cases techniques (agents, MCP, API, versioning via Git…). LangChain est le pionnier historique pour les chaînes linéaires, tandis que LangGraph permet de créer des workflows circulaires hyper complexes.
- Le hic : Ils sont codés en Python. Et chez nous, le Python, ce n’est pas notre langue maternelle ! La marche était haute, surtout pour LangChain. On a senti que la courbe d’apprentissage allait nous ralentir sérieusement avant de sortir quoi que ce soit de concret.
- LLPhant : Le challenger prometteur Inspiré de LangChain mais en PHP, c’est une librairie orientée code et la gestion de l’orchestration, des erreurs, des connecteurs etc… nous appartient. Plus de contrôle mais au prix d’un efforts techniques importants qui vont vite augmenter le temps de dev. De plus cette librairie est encore un peu jeune même si elle semble être bien maintenue.
- N8N : L’outsider visuel Lui aussi valide nos pré-requis techniques (agents, API, MCP). Pour le versioning, c’est un peu différent (historique intégré ou sauvegarde Git en version payante), mais il compense par une bibliothèque d’outils intégrés phénoménale (Google, Slack, Discord, etc.).
- Le gros plus : C’est visuel et donc facilement accessible à l’équipe produit aussi! La prise en main est ultra-rapide et on peut même ajouter des évaluations sur les workflows pour valider que nos agents ne font pas n’importe quoi.
🎉 Le grand gagnant : N8N ! Pourquoi ce choix ?
Alors, pourquoi avons-nous finalement opté pour N8N ?
Même si les frameworks en pur code sont puissants, N8N nous permettra de construire des workflows complexes sans passer trois mois en formation. Pour faire des POCs et valider nos idées rapidement, c’est idéal.
Et l’industrialisation dans tout ça ?
C’est vrai, le déploiement en production sur nos plateformes Self-Hosted est encore un point d’interrogation. Mais on a décidé de mettre ce sujet de côté pour le moment. Pourquoi ? Parce que l’enjeu de notre premier cycle sur l’IA était de tester, tester et encore tester.
On veut d’abord trouver la bonne granularité pour nos agents et peaufiner nos prompts. Dans cet écosystème qui bouge à une vitesse folle, se poser la question de l’industrialisation aujourd’hui alors que de meilleures solutions existeront peut-être dans six semaines, c’était prématuré. On valide l’idée d’abord, on industrialise ensuite !
🗓️ Et après quelques semaines d’utilisation, on en est où ?
Après quelques semaines de travail avec N8N, le bilan est très positif. On a confirmé que :
- Ne pas avoir à coder dans un langage que nous ne connaissions pas ainsi que l’ensemble des outils fournis par N8N nous ont permis de faire en peu de temps des workflows assez complexes, puissants et testés/évalués.
- Le côté visuel est un énorme avantage pour l’équipe Produit, qui peut suivre l’avancement des automatisations sans plonger dans le code.
- L’intégration avec notre environnement IA privé fonctionne parfaitement, nous maintient dans notre budget (pas de tokens !) et notre niveau de sécurité exigé.
Le choix de N8N a donc validé notre méthodologie : prendre le temps de bien cadrer les contraintes, sécuriser l’Infra et faire des tests rapides nous a permis de choisir l’outil le plus adapté à notre réalité du moment.
III. Comment monter en compétences en tant qu’équipe de développement ?
Ok, on a choisi nos outils, mais comment on fait pour que toute l’équipe soit au top et sache les utiliser sans stress ? On est tous d’accord : se former, ça prend du temps et ça demande de la pratique, surtout quand il s’agit de l’IA !
Voici comment on a organisé notre montée en compétences en créant un environnement optimal pour l’apprentissage :
1. Sécurité d’abord : Un bac à sable pour s’amuser sans danger
Quand on parle d’apprentissage et d’expérimentation, on a besoin d’un terrain de jeu où on peut faire des bêtises sans conséquences. Chez nous, c’était une nécessité absolue, surtout avec notre certification ISO 27001.
- Le Cadeau de l’Infra : Comme on l’a vu notre équipe Infra nous a mis à disposition un environnement interne et sécurisé. C’est un peu notre “bac à sable” Yogosha !
- L’avantage ? On peut essayer de connecter tous nos outils internes, tester des configurations bizarres, et même faire des erreurs… sans jamais mettre en danger nos systèmes de production ou nos données clients. C’est l’endroit parfait pour s’amuser en toute sécurité !
2. Dédier du temps pour apprendre (et souffler !)
La meilleure formation, c’est celle qu’on a le temps de suivre sans la pression de la production. Et pour ça l’utilisation de la méthodo Shape Up est top, elle met à disposition 2 semaines dédiées à l’amélioration continue.
On a donc profité des deux semaines de cooldown qui précédaient notre premier cycle de travail sur l’IA pour s’y mettre et en faire un temps d’apprentissage pur.
⇒ Zéro Pression : On a pu lire des articles, regarder des vidéos, et faire nos premiers tests sans avoir l’épée de Damoclès des livrables au-dessus de la tête. C’était l’idéal pour commencer sereinement!
3. Pratiquer, pratiquer, pratiquer !
L’IA, ce n’est pas que de la théorie. Il faut mettre les mains dans le cambouis :
- Temps de Dev et d’Expérimentation : On a clairement dédié du temps aux développeurs pour qu’ils puissent expérimenter les nouvelles technos que nous avions choisies. C’est du temps de travail, pas du temps “en plus” ! Pour cela un cycle complet (6 semaines) a été dédié à mettre en place des POCs.
- Le Pair Programming (Pair Prog) : La meilleure façon d’apprendre vite et bien, c’est d’être deux. On est tous en full-remote, pas de soucis, une visio avec partage d’écran et c’est parti! Un qui code, l’autre qui observe et conseille. Ça permet de transmettre les connaissances super rapidement, d’échanger des points de vue directement en évitant de rester bloqué tout seul pendant des heures.
4. Partager et échanger : L’intelligence collective

L’apprentissage est une aventure collective ! Pour que l’expertise se diffuse dans toute l’équipe, et au delà, on a misé sur le partage continu :
- Les Tech Reviews (1h par semaine) : Pour s’assurer que nos choix techniques sont solides et que l’on respecte les bonnes pratiques. C’est un moment critique et formateur.
- Les Démos (dès que possible) : Montrer ce qu’on a réussi à faire (ou même nos échecs constructifs !) aux autres. Voir la techno en action, ça rend les choses beaucoup plus claires pour tout le monde!
- Les Geek Fridays (1/2 journée par cool-down): C’est notre moment informel pour échanger sur nos découvertes, nos coups de cœur technos, nos lectures… Parfait pour partager les articles et les vidéos les plus pertinents qu’on a trouvés sur l’IA !
VI. Comment maîtriser les coûts de la phase de POC
Innover c’est bien mais encore faut-il ne pas se ruiner inutilement! Et quand on parle d’IA on a vite fait d’affoler les compteurs…
Côté Infra : Un coût maîtrisé pour assurer la sécurité des données
On vous le disait, on a opté pour un serveur dédié avec une carte H100. C’est le top du top pour la sécurité, mais ça pique un peu : environ 2500 €/mois. C’est le prix de la tranquillité pour nos données clients confidentielles.
Mais on a trouvé une parade pour alléger la facture pendant la phase de test :
- Le serveur “aux 35 heures” (ou presque) : Pourquoi laisser une machine de guerre tourner à plein régime quand l’équipe dort ? On a donc programmé l’ouverture du serveur sur une plage horaire définie : 12h par jour, 5 jours par semaine. Verdict : la facture est tombée de 2500 € à 800 €/mois. Une économie massive sans impacter notre capacité à bosser !
- N8N en mode “Budget” : Pour l’outil d’automatisation, on a commencé avec la version gratuite. Certes, il nous manque quelques options (comme le versioning des workflows), mais c’est largement suffisant pour valider nos idées sans sortir la carte bleue tout de suite.
Côté Gestion de Projet : La méthode “Shape Up” à la rescousse
Au-delà de la technique, c’est notre façon de travailler qui nous protège des projets qui n’en finissent plus. On utilise la méthodologie Shape Up.
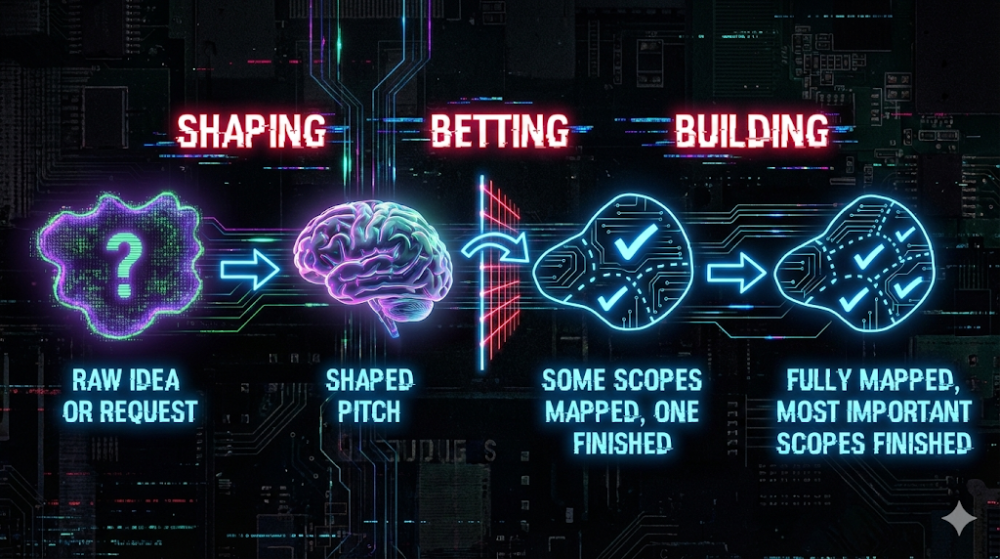
Le principe ? On travaille par cycles de 6 semaines.
- Un cadre strict : Pour ce sujet IA, on s’est donné 6 semaines pour sortir des résultats. Pas une de plus ! Peu importe où on en est à la fin du chrono, on s’arrête et on fait l’état des lieux. Ça évite l’effet “tunnel” où on dépense sans voir le bout.
- La “Betting Table” (Le moment de vérité) : C’est là que tout se joue. À la fin du cycle, on réunit les stakeholders (les parties prenantes). On leur montre ce qu’on a fait, la maturité du sujet, et on discute.
- On continue ou on arrête ? C’est une décision collective. Soit on décide de “remettre une pièce dans la machine” parce que le potentiel est là, soit on priorise un autre sujet plus urgent. On choisit ensemble, en toute connaissance de cause, si l’investissement en vaut encore la chandelle.
En résumé : Entre les horaires de bureau de notre serveur et le cadre strict de nos cycles de 6 semaines, on a réussi à transformer un sujet complexe et coûteux en une expérimentation maîtrisée et hyper réactive.
Le mot de la fin : d’une intuition à une réalité maîtrisée
Chez Yogosha en trois mois, nous sommes passés d’une réflexion stratégique sur l’IA à une réalité opérationnelle où nos équipes “shippent” des agents concrets. Si nous devions résumer ce que nous avons appris en ouvrant le capot, c’est que la technique ne vaut rien sans méthode.
Choisir N8N n’était pas seulement un choix d’outil, c’était le choix de l’agilité et de l’accessibilité. Construire notre propre infrastructure privée, ce n’était pas par pur plaisir de “Geek”, mais pour garantir à nos clients une sécurité sans compromis. Et enfin, utiliser les Spikes et la méthodologie Shape Up, c’était notre garde-fou pour ne jamais laisser l’innovation dériver en gouffre financier.
💡 Takeaways : 6 clés pour un pivot IA
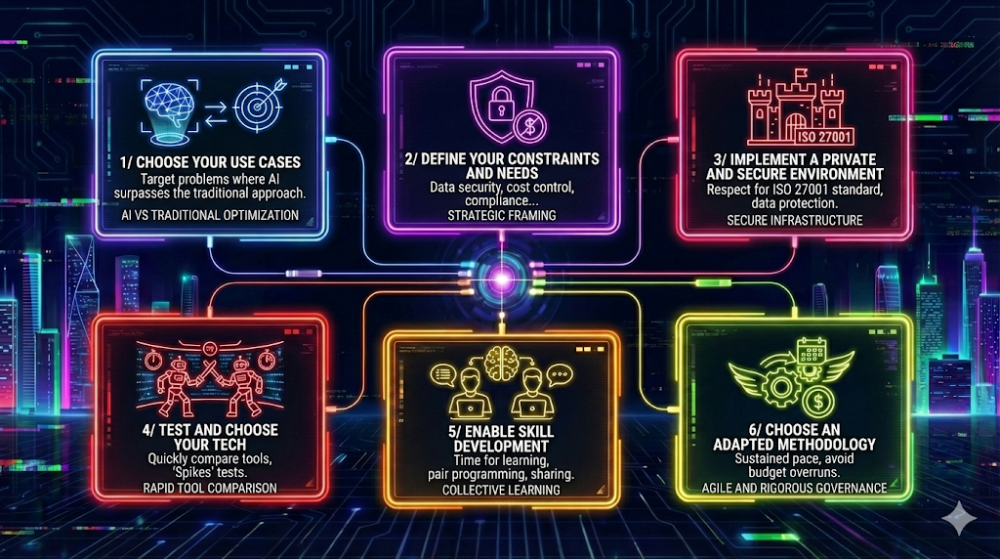
Si vous devez retenir l’essentiel de notre démarche pour votre propre organisation, voici les points essentiels :
- Choisir ses cas d’usage en lien avec la réalité du business
- Définir ses contraintes et besoins avant de se lancer
- Mettre en place son environnement sécurisé (et privé si possible)
- Tester et choisir sa techno en 3 jours
- Prendre le temps de la montée en compétence … au moins 2 semaines full
- Choisir une méthodologie adapté à la dynamique d’expérimentation frugale
Le momentum est là, les outils sont en place, et l’équipe est montée en puissance. Mais le voyage ne s’arrête pas à la validation d’un POC. Le prochain défi ? Transformer ces essais en fonctionnalités industrielles au cœur de notre plateforme!
👉 Découvrez notre article IA : Passer du POC à la Feature : industrialiser l’IA en toute sécurité.
Et vous ? Comment avez-vous abordé ces enjeux d’organisation et de montée en compétences ? Entre la gestion du temps, le choix des technos et la maîtrise des coûts, quelles solutions avez-vous testées et approuvées au sein de vos équipes ?






